No free lunch in community detection?
The “no free lunch” scenario is incompatible with Occam’s razor.
For a wide class of optimization and learning problems there exist so-called “no-free-lunch” (NFL) theorems, which broadly state that when averaged over all possible problem instances, all algorithms show equivalent performance [2–4]. Peel et al [5] have proved that this is also valid for the problem of community detection, meaning that no single method can perform systematically better than any other, when averaged over “all community detection problems.” This has been occasionally interpreted as a reason to reject the claim that we should prefer certain classes of algorithms over others. This is, however, a misinterpretation of the theorem, as we will now discuss.
The NFL theorem for community detection is easy to state. Let us consider a generic community detection algorithm indexed by \(f\), defined by the function \(\hat{\boldsymbol b}_f(\boldsymbol A)\), which ascribes a single partition to a network \(\boldsymbol A\). Peel et al [5] consider an instance of the community detection problem to be an arbitrary pair \((\boldsymbol A,\boldsymbol b)\) composed of a network \(\boldsymbol A\) and the correct partition \(\boldsymbol b\) that one wants to find from \(\boldsymbol A\). We can evaluate the accuracy of the algorithm \(f\) via an error (or “loss”) function
\[\epsilon (\boldsymbol b, \hat{\boldsymbol b}_f(\boldsymbol A))\]
which should take the smallest possible value if \(\hat{\boldsymbol b}_f(\boldsymbol A) = \boldsymbol b\). If the error function does not have an inherent preference for any partition (it's “homogeneous”), then the NFL theorem states [3,5].
\[\sum_{(\boldsymbol A, \boldsymbol b)}\epsilon (\boldsymbol b, \hat{\boldsymbol b}_f(\boldsymbol A)) = \Lambda(\epsilon), \tag{1}\]
where \(\Lambda(\epsilon)\) is a value that depends only on the error function chosen, but not on the community detection algorithm \(f\). In other words, when averaged over all problem instances, all algorithms have the same accuracy. This implies, therefore, that in order for one class of algorithms to perform systematically better than another, we need to restrict the universe of problems to a particular subset. This is a seemingly straightforward result, but which is unfortunately very susceptible to misinterpretation and overstatement.
A common criticism of this kind of NFL theorem is that it is a poor representation of the typical problems we may encounter in real domains of application, which are unlikely to be uniformly distributed across the entire problem space. Therefore, as soon as we constrain ourselves to a subset of problems that are relevant to a particular domain, then this will favor some algorithms over others — but then no algorithm will be superior for all domains. But since we are typically only interested in some domains, the NFL theorem is then arguably “theoretically sound, but practically irrelevant” [6]. Although indeed correct, in the case of community detection this logic is arguably an understatement. This is because as soon as we restrict our domain to community detection problems that reveal something informative about the network structure, then we are out of reach of the NFL theorem, and some algorithms will do better than others, without evoking any particular domain of application. We demonstrate this in the following.
The framework of the NFL theorem operates on a liberal notion of what constitutes a community detection problem and its solution, which means for an arbitrary pair \((\boldsymbol A,\boldsymbol b)\) choosing the right \(f\) such that \(\hat{\boldsymbol b}_f(\boldsymbol A)=\boldsymbol b.\) Under this framework, algorithms are just arbitrary mappings from network to partition, and there is no necessity to articulate more specifically how they relate to the structure of the network — community detection just becomes an arbitrary game of “guess the hidden node labels.” This contrasts with how actual community detection algorithms are proposed, which attempt to match the node partitions to patterns in the network, e.g. assortativity, general connection preferences between groups, etc. Although the large variety of algorithms proposed for this task already reveal a lack of consensus on how to precisely define it, few would consider it meaningful to leave the class of community detection problems so wide open as to accept any matching between an arbitrary network and an arbitrary partition as a valid instance.
Even though we can accommodate any (deterministic) algorithm deemed valid according to any criterion under the NFL framework, most algorithms in this broader class do something else altogether. In fact, the absolute vast majority of them correspond to a maximally random matching between network and partition, which amounts to little more than just randomly guessing a partition for any given network, i.e. they return widely different partitions for inputs that are very similar, and overall point to no correlation between input and output.1 It is not difficult to accept that these random algorithms perform equally “well” for any particular problem, or even all problems, but the NFL theorem says that they have equivalent performance even to algorithms that we may deem more meaningful. How do we make a formal distinction between algorithms that are just randomly guessing from those that are doing something coherent, that depends on discovering actual network patterns? As it turns out, there is an answer to this question that does not depend on particular domains of application: we require the solutions found to be structured and compressive of the network.
1 An interesting exercise is to count how many such algorithms exist. A given community detection algorithm \(f\) needs to map each of all \(\Omega(N)=2^{N\choose 2}\) networks of \(N\) nodes to one of \(\Xi(N)=\sum_{B=1}^{N}\genfrac\{\}{0pt}{}{N}{B}B!\) labeled partitions of its nodes. Therefore, if we restrict ourselves to a single value of \(N\), the total number of input-output tables is \(\Xi(N)^{\Omega(N)}\). If we sample one such table uniformly at random, it will be asymptotically impossible to compress it using fewer than \(\Omega(N)\log_2\Xi(N)\) bits — a number that grows super-exponentially with \(N\). As an illustration, a random community detection algorithm that works only with \(N=100\) nodes would already need \(10^{1479}\) terabytes of storage. Therefore, simply considering algorithms that humans can write and use (together with their expected inputs and outputs) already pulls us very far away from the general scenario considered by the NFL theorem.
In order to interpret the statement of the NFL theorem in this vein, it is useful to re-write Equation 1 using an equivalent probabilistic language,
\[\sum_{\boldsymbol A, \boldsymbol b}P(\boldsymbol A,\boldsymbol b)\epsilon (\boldsymbol b, \hat{\boldsymbol b}_f(\boldsymbol A)) = \Lambda'(\epsilon), \tag{2}\]
where \(\Lambda'(\epsilon)\propto \Lambda(\epsilon)\), and \(P(\boldsymbol A,\boldsymbol b) \propto 1\) is the uniform probability of encountering a problem instance. When writing the theorem statement in this way, we notice immediately that instead of being agnostic about problem instances, it implies a very specific network generative model, which assumes a complete independence between network and partition. Namely, if we restrict ourselves to networks of \(N\) nodes, we have then:
\[\begin{aligned} \begin{aligned} P(\boldsymbol A,\boldsymbol b)&=P(\boldsymbol A)P(\boldsymbol b),\\ P(\boldsymbol A) &= 2^{-{N\choose 2}},\\ P(\boldsymbol b) &= \left[\sum_{B=1}^{N}\genfrac\{\}{0pt}{}{N}{B}B!\right]^{-1}. \end{aligned} \end{aligned} \tag{3}\]
Therefore, the NFL theorem states simply that if we sample networks and partitions from a maximally random generative model, then all algorithms will have the same average accuracy at inferring the partition from the network. This is hardly a spectacular result — indeed the Bayes-optimal algorithm in this case, i.e. the one derived from the posterior distribution of the true generative model and which guarantees the best accuracy on average, consists of simply guessing partitions uniformly at random, ignoring the network structure altogether.
The probabilistic interpretation reveals that the NFL theorem makes a very specific assumption about what kind of community detection problem we are expecting, namely one where both the network and partition are sampled independently and uniformly at random. It is important to remember that it is not possible to make “no assumption” about a problem; we are always forced to make some assumption, which even if implicit does not exempt it from justification, and the uniform assumption of Equation 3 is no exception. In Figure 1 (a) we show a typical sample from this ensemble of community detection problems.
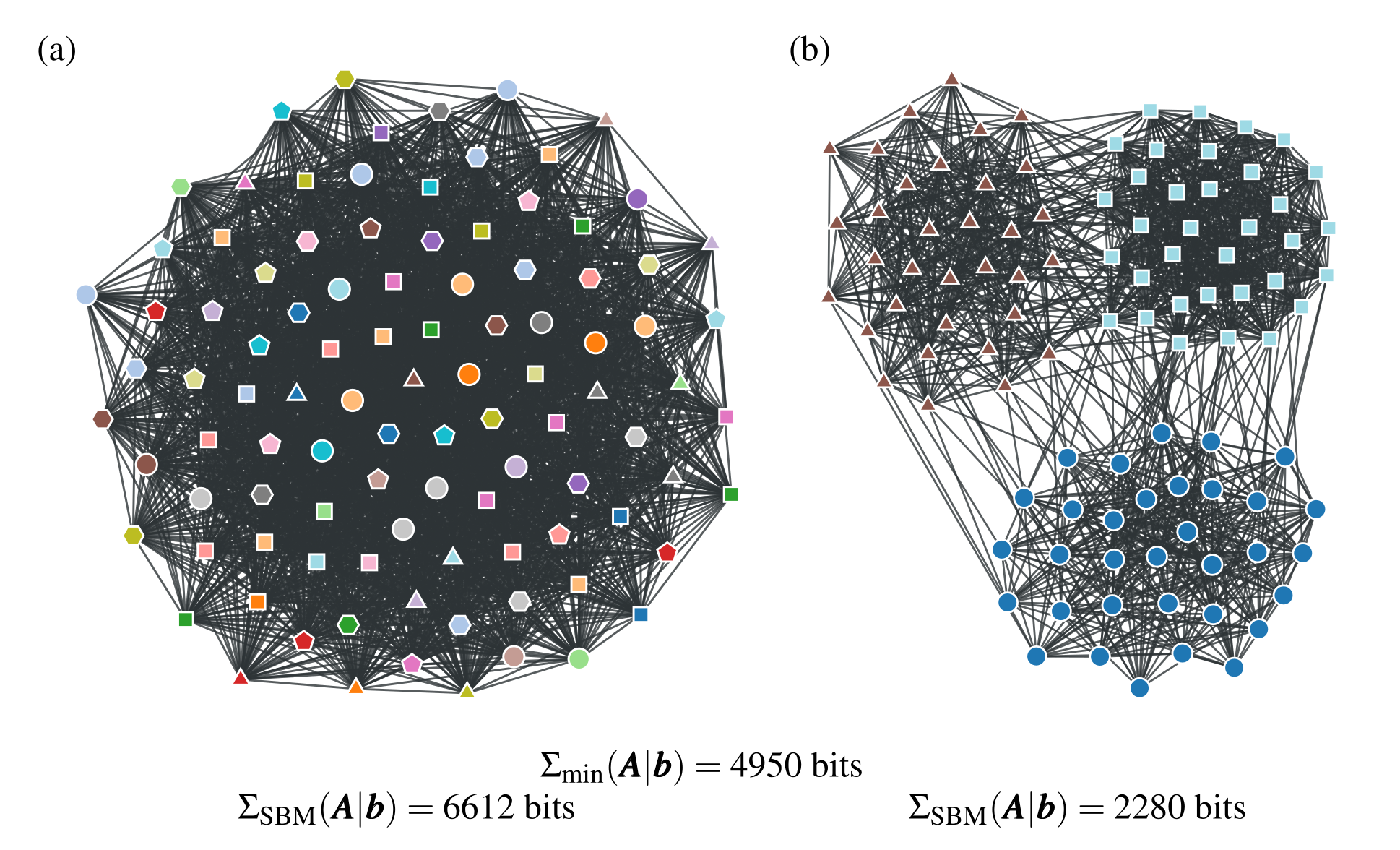
In a very concrete sense, we can state that such problem instances contain no learnable community structure, or in fact no learnable network structure at all. We say that a community structure is learnable if the knowledge of the partition \(\boldsymbol b\) can be used to compress the network \(\boldsymbol A\), i.e. there exists an encoding \(\mathcal{H}\) (i.e. a generative model) such that
\[\begin{aligned} \begin{aligned} \Sigma(\boldsymbol A|\boldsymbol b,\mathcal{H}) &< -\log_2 P(\boldsymbol A),\\ &< {N\choose 2}, \end{aligned} \end{aligned}\]
where \(\Sigma(\boldsymbol A|\boldsymbol b,\mathcal{H}) = -\log_2P(\boldsymbol A|\boldsymbol b,\mathcal{H})\) is the description length of \(\boldsymbol A\) according to model \(\mathcal{H}\), conditioned on the partition being known. However, it is a direct consequence of Shannon's source coding theorem [7], that for the vast majority of networks sampled from the model of Equation 3 the inequality above cannot be fulfilled as \(N\to\infty\), i.e. the networks are incompressible.2 This means that the true partition \(\boldsymbol b\) carries no information about the network structure, and vice versa, i.e. the partition is not learnable from the network. In view of this, the common interpretation of the NFL theorem as “all algorithms perform equally well” is in fact somewhat misleading, and can be more accurately phrased as “all algorithms perform equally poorly”, since no inferential algorithm can uncover the true community structure in most cases, at least no better than by chance alone. In other words, the universe of community detection problems considered in the NFL theorem is composed overwhelmingly of problems for which compression and explanation are not possible.3 This uniformity between instances also reveals that there is no meaningful trade-off between algorithms for most instances, since all algorithms will yield the same negligible asymptotic performance, with an accuracy tending asymptotically towards zero as the number of nodes increases. In this setting, there is not only no free lunch, but in fact there is no lunch at all (see Figure 2).
2 For finite networks a positive compression might be achievable with small probability, but due to chance alone, and not in a manner that makes its structure learnable.
3 One could argue that such a uniform model is justified by the principle of maximum entropy, which states that in the absence of prior knowledge about which problem instances are more likely, we should assume they are all equally likely a priori. This argument fails precisely because we do have sufficient prior knowledge that empirical networks are not maximally random — specially those possessing community structure, according to any meaningful definition of the term. Furthermore, it is easy to verify for each particular problem instance that the uniform assumption does not hold; either by compressing an observed network using any generative model (which should be asymptotically impossible under the uniform assumption), or performing a statistical test designed to reject the uniform null model. It is exceedingly difficult to find an empirical network for which the uniform model cannot be rejected with near-absolute confidence.

If we were to restrict the space of possible community detection algorithms to those that provide actual explanations, then by definition this would imply a positive correlation between network and partition, i.e.4
4 Note that Equation 4 is a necessary but not sufficient condition for the community detection problem to be solvable. An example of this are networks generated by the SBM, which are solvable only if the strength of the community structure exceeds a detectability threshold [8], even if Equation 4 is fulfilled.
\[\begin{aligned} \begin{aligned} P(\boldsymbol A,\boldsymbol b) &= P(\boldsymbol A|\boldsymbol b)P(\boldsymbol b)\\ &\neq P(\boldsymbol A)P(\boldsymbol b). \end{aligned} \end{aligned} \tag{4}\]
Not only this implies a specific generative model but, as a consequence, also an optimal community detection algorithm, that operates based on the posterior distribution
\[P(\boldsymbol b|\boldsymbol A) = \frac{P(\boldsymbol A|\boldsymbol b)P(\boldsymbol b)}{P(\boldsymbol A)}.\]
Therefore, learnable community detection problems are invariably tied to an optimal class of algorithms, undermining to a substantial degree the relevance of the NFL theorem in practice. In other words, whenever there is an actual community structure in the network being considered — i.e. due to a systematic correlation between \(\boldsymbol A\) and \(\boldsymbol b\), such that \(P(\boldsymbol A,\boldsymbol b)\ne P(\boldsymbol A)P(\boldsymbol b)\) — there will be algorithms that can exploit this correlation better than others (see Figure 1 (b) for an example of a learnable community detection problem). Importantly, the set of learnable problems form only an infinitesimal fraction of all problem instances, with a measure that tends to zero as the number of nodes increases, and hence remain firmly out of scope of the NFL theorem. This observation has been made before, and is equally valid, in the wider context of NFL theorems beyond community detection [9–14].
Note that since there are many ways to choose a nonuniform model according to Equation 4, the optimal algorithms will still depend on the particular assumptions made via the choice \(P(\boldsymbol A,\boldsymbol b)\). However, this does not imply that all algorithms have equal performance on compressible problem instances. If we sample a problem from the universe \(\mathcal{H}_1\), with \(P(\boldsymbol A,\boldsymbol b|\mathcal{H}_1)\), but use instead two algorithms optimal in \(\mathcal{H}_2\) and \(\mathcal{H}_3\), respectively, their relative performances will depend on how close each of these universes is to \(\mathcal{H}_1\), and hence will not be in general the same. In fact, if our space of universes is finite, we can compose them into a single unified universe [15] according to
\[P(\boldsymbol A,\boldsymbol b) = \sum_{i=1}^{M}P(\boldsymbol A,\boldsymbol b|\mathcal{H}_i)P(\mathcal{H}_i),\]
which will incur a compression penalty of at most \(\log_2 M\) bits added to the description length of the optimal algorithm. This gives us a path, based on hierarchical Bayesian models and minimum description length, to achieve optimal or near-optimal performance on instances of the community detection problem that are actually solvable, simply by progressively expanding our set of hypotheses.
The idea that we can use compression as an inference criterion has been formalized by Solomonoff's theory of inductive inference, which forms a rigorous induction framework based on the principle of Occam's razor. Importantly, the expected errors of predictions achieved under this framework are provably upper-bounded by the Kolmogorov complexity of the data generating process [16], making the induction framework consistent. The Kolmogorov complexity is a generalization of the description length we have been using, and it is defined by the length of the shortest binary program that generates the data. The only major limitation of Solomonoff's framework is its uncomputability, i.e. the impossibility of determining Kolmogorov's complexity with any algorithm. However, this impossibility does not invalidate the framework, it only means that induction cannot be fully automatized: we have a consistent criterion to compare hypotheses, but no deterministic mechanism to produce directly the best hypothesis. There are open philosophical questions regarding the universality of this inductive framework [18], but whatever fundamental limitations it may have do not follow directly from NFL theorems such as the one from [5]. In fact, as mentioned in the footnote above, it is a rather simple task to use compression to reject the uniform hypothesis forming the basis of the NFL theorem for almost any network data.
Since compressive community detection problems are out of the scope of the NFL theorem, it is not meaningful to use it to justify avoiding comparisons between algorithms, on the grounds that all choices must be equally “good” in a fundamental sense. In fact, we do not need much sophistication to reject this line of argument, since the NFL theorem applies also when we are considering trivially inane algorithms, e.g. one that always returns the same partition for every network. The only domain where such an algorithm is as good as any other is when we have no community structure to begin with, which is precisely what the NFL theorem relies on.
Nevertheless, there are some lessons we can draw from the NFL theorem. It makes it clear that the performance of algorithms are tied directly to the inductive bias adopted, which should always be made explicit. The superficial interpretation of the NFL theorem as an inherent equity between all algorithms stems from the assumption that considering all problem instances uniformly is equivalent to being free of an inductive bias, but that is not possible. The uniform assumption is itself an inductive bias, and one that it is hard to justify in virtually any context, since it involves almost exclusively unsolvable problems (from the point of view of compressibility). In contrast, considering only compressible problem instances is also an inductive bias, but one that relies only on Occam's razor as a guiding principle. The advantage of the latter is that it is independent of domain of application, i.e. we are making a statement only about whether a partition can help explaining the network, without having to specify how a priori.
In view of the above observations, it becomes easier to understand results such as of Ghasemian et al [19] who found that compressive inferential community detection methods tend to systematically outperform descriptive methods in empirical settings, when these are employed for the task of edge prediction. Even though edge prediction and community detection are not the same task, and using the former to evaluate the latter can lead in some cases to overfitting [20], typically the most compressive models will also lead to the best generalization. Therefore, the superior performance of the inferential methods is understandable, even though Ghasemian et al also found a minority of instances where some descriptive methods can outperform inferential ones. To the extent that these minority results cannot be attributed to overfitting, or technical issues such as insufficient MCMC equilibration, it could simply mean that the structure of these networks fall sufficiently outside of what is assumed by the inferential methods, but without it being a necessary trade-off that comes as a consequence of the NFL theorem — after all, under the uniform assumption, edge prediction is also strictly impossible, just like community detection. In other words, these results do not rule out the existence of an algorithm that works better in all cases considered, at least if their number is not too large 5. In fact, this is precisely what is achieved in [21] via model stacking, i.e. a combination of several predictors into a meta-predictor that achieves systematically superior performance. This points indeed to the possibility of using universal methods to discover the latent compressive modular structure of networks, without any tension with the NFL theorem.
5 It is important to distinguish the actual statement of the NFL theorem — “all algorithms perform equally well when averaged over all problem instances” — from the alternative statement: “No single algorithm exhibits strictly better performance than all others over all instances.” Although the latter is a corollary of the former, it can also be true when the former is false. In other words, a particular algorithm can be better on average over relevant problem instances, but still underperform for some of them. In fact, it would only be possible for an algorithm to strictly dominate all others if it can always achieve perfect accuracy for every instance. Otherwise, there will be at least one algorithm (e.g. one that always returns the same partition) that can achieve perfect accuracy for a single network where the optimal algorithm does not (“even a broken clock is right twice a day”). Therefore, sub-optimal algorithms can eventually outperform optimal ones by chance when a sufficiently large number of instances is encountered, even when the NFL theorem is not applicable (and therefore this fact is not necessarily a direct consequence of it).
References
Webmentions6
(Nothing yet)
6 Webmention is a standardized decentralized mechanism for conversations and interactions across the web.
Comments