Modularity maximization considered harmful
The most widespread method for community detection is modularity maximization [2], which happens also to be one of the most problematic. This method is based on the modularity function,
\[Q(\boldsymbol A,\boldsymbol b) = \frac{1}{2E}\sum_{ij}\left(A_{ij} - \frac{k_ik_j}{2E}\right)\delta_{b_i,b_j} \tag{1}\]
where \(A_{ij}\in\{0,1\}\) is an entry of the adjacency matrix, \(k_i=\sum_jA_{ij}\) is the degree of node \(i\), \(b_i\) is the group membership of node \(i\), and \(E\) is the total number of edges. The method consists in finding the partition \(\hat{\boldsymbol b}\) that maximizes \(Q({\boldsymbol A},{\boldsymbol b})\),
\[\hat{\boldsymbol b} = \underset{\boldsymbol b}{\operatorname{argmax}}\; Q(\boldsymbol A,\boldsymbol b). \tag{2}\]
The motivation behind the modularity function is that it compares the existence of an edge \((i,j)\) to the probability of it existing according to a null model, \(P_{ij} = k_ik_j/2E\), namely that of the configuration model [3] (or more precisely, the Chung-Lu model [4]). The intuition for this method is that we should consider a partition of the network meaningful if the occurrence of edges between nodes of the same group exceeds what we would expect with a random null model without communities.
Despite its widespread adoption, this approach suffers from a variety of serious conceptual and practical flaws, which have been documented extensively [9]. The most problematic one is that it purports to use an inferential criterion—a deviation from a null generative model—but is in fact merely descriptive. As has been recognized very early, this method categorically fails in its own stated goal, since it always finds high-scoring partitions in networks sampled from its own null model [5].
The reason for this failure is that the method does not take into account the deviation from the null model in a statistically consistent manner. The modularity function is just a re-scaled version of the assortativity coefficient [10], a correlation measure of the community assignments seen at the endpoints of edges in the network. We should expect such a correlation value to be close to zero for a partition that is determined before the edges of the network are placed according to the null model, or equivalently, for a partition chosen at random. However, it is quite a different matter to find a partition that optimizes the value of \(Q({\boldsymbol A},{\boldsymbol b})\), after the network is observed. The deviation from a null model computed in Equation 1 completely ignores the optimization step of Equation 2, although it is a crucial part of the algorithm. As a result, the method of modularity maximization tends to massively overfit, and find spurious communities even in networks sampled from its null model. We are searching for patterns of correlations in a random graph, and most of the time we will find them. This is a pitfall known as “data dredging” or “p-hacking”, where one searches exhaustively for different patterns in the same data and reports only those that are deemed significant, according to a criterion that does not take into account the fact that we are doing this search in the first place.
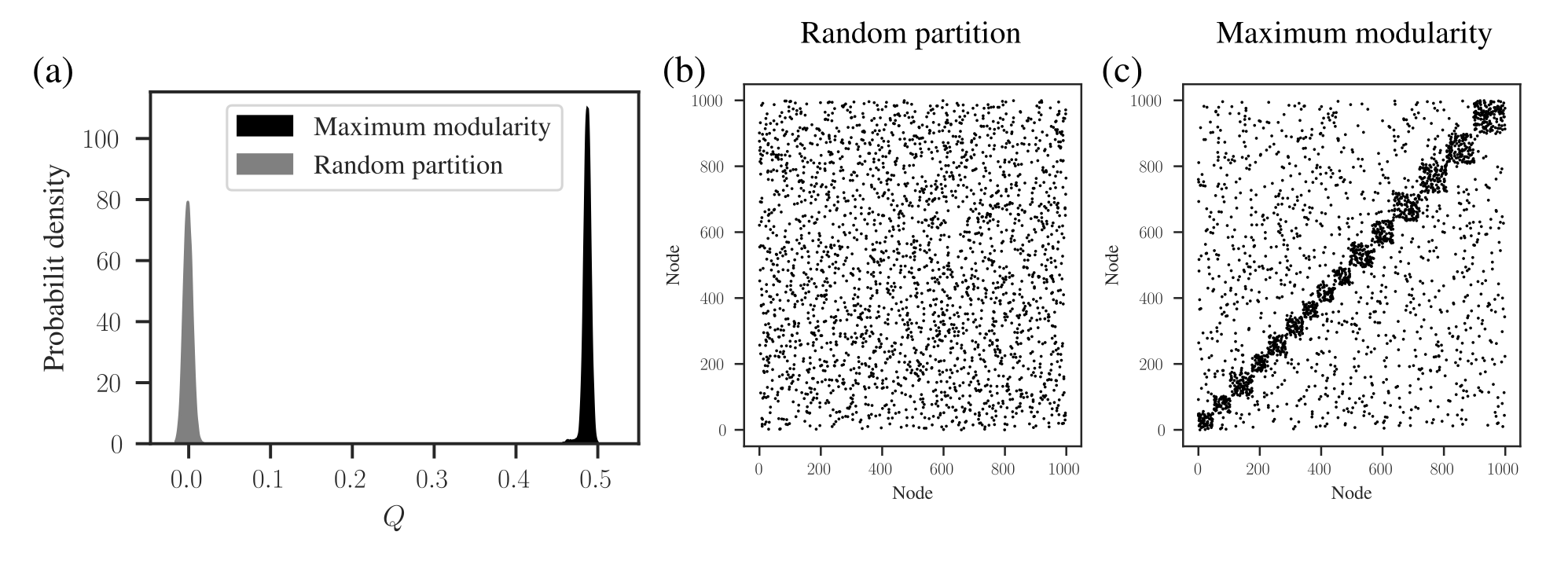
We demonstrate this problem in Figure 1, where we show the distribution of modularity values obtained with a uniform configuration model with \(k_i=5\) for every node \(i\), considering both a random partition and the one that maximizes \(Q({\boldsymbol A},{\boldsymbol b})\). While for a random partition we find what we would expect, i.e. a value of \(Q({\boldsymbol A},{\boldsymbol b})\) close to zero, for the optimized partition the value is substantially larger. Inspecting the optimized partition in Figure 1 (c), we see that it corresponds indeed to 15 seemingly clear assortative communities—which by construction bear no relevance to how the network was generated. They have been dredged out of randomness by the optimization procedure.
Somewhat paradoxically, another problem with modularity maximization is that in addition to systematically overfitting, it also systematically underfits. This occurs via the so-called “resolution limit”: in a connected network1 the method cannot find more than \(\sqrt{2E}\) communities [6], even if they seem intuitive or can be found by other methods. An example of this is shown in Figure 2, where for a network generated with the SBM containing 30 communities, modularity maximization finds only 18, while an inferential approach has no problems finding the true structure. There are attempts to counteract the resolution limit by introducing a “resolution parameter” to the modularity function, but they are in general ineffective [see 1].
1 Modularity maximization, like many descriptive community detection methods, will always place connected components in different communities. This is another clear distinction with inferential approaches, since fully random models—without latent community structure—can generate disconnected networks if they are sufficiently sparse. From an inferential point of view, it is therefore incorrect to assume that every connected component must belong to a different community.
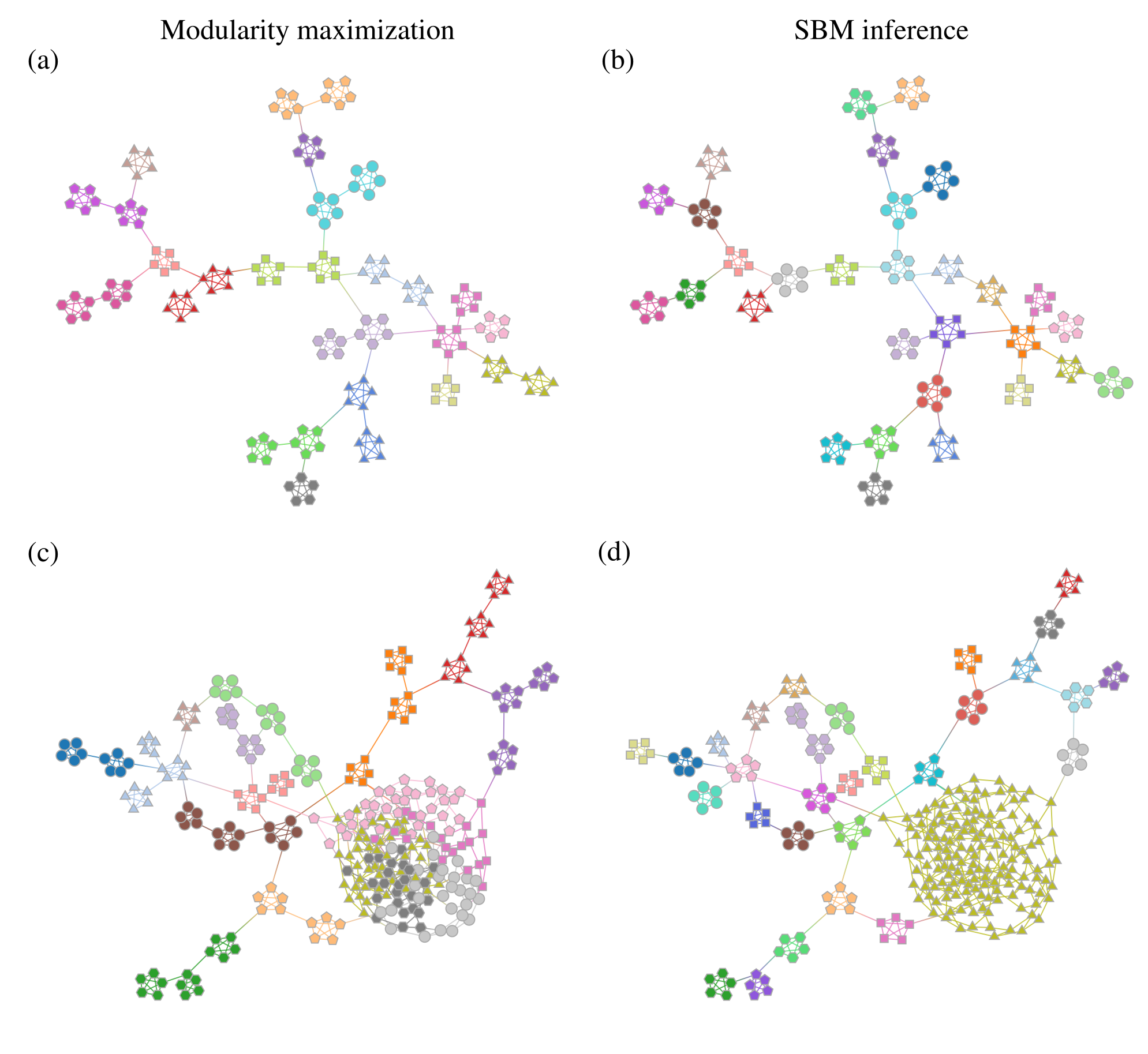
These two problems—overfitting and underfitting—can occur in tandem, such that portions of the network dominated by randomness are spuriously revealed to contain communities, whereas other portions with clear modular structure can have those obstructed. The result is a very unreliable method to capture the structure of heterogeneous networks. We demonstrate this in Figure 2 (c) and (d)
In addition to these major problems, modularity maximization also often possesses a degenerate landscape of solutions, with very different partitions having similar values of \(Q({\boldsymbol A},{\boldsymbol b})\) [7]. In these situations the partition with maximum value of modularity can be a poor representative of the entire set of high-scoring solutions and depend on idiosyncratic details of the data rather than general patterns—which can be interpreted as a different kind of overfitting.
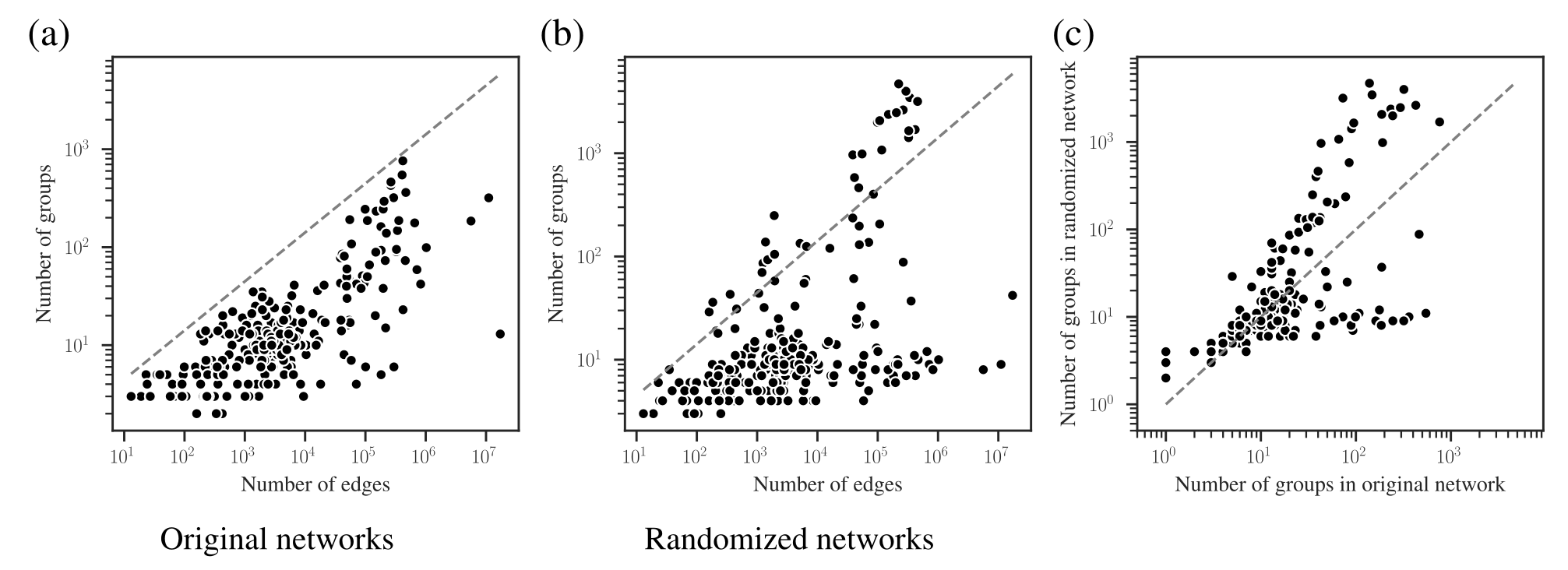
The combined effects of underfitting and overfitting can make the results obtained with the method unreliable and difficult to interpret. As a demonstration of the systematic nature of the problem, in Figure 3 (a) we show the number of communities obtained using modularity maximization for 263 empirical networks of various sizes and belonging to different domains, obtained from the Netzschleuder repository. Since the networks considered are all connected, the values are always below \(\sqrt{2E}\), due to the resolution limit; but otherwise they are well distributed over the allowed range. However, in Figure 3 (b) we show the same analysis, but for a version of each network that is fully randomized, while preserving the degree sequence. In this case, the number of groups remains distributed in the same range (sometimes even exceeding the resolution limit, because the randomized versions can end up disconnected). As Figure 3 (c) shows, the number of groups found for the randomized networks is strongly correlated with the original ones, despite the fact that the former have no latent community structure. This is a strong indication of the substantial amount of noise that is incorporated into the partitions found with the method.
The systematic overfitting of modularity maximization—as well as other descriptive methods such as Infomap—has been also demonstrated recently in [12], from the point of view of edge prediction, on a separate empirical dataset of 572 networks from various domains.
Although many of the problems with modularity maximization were long known, for some time there were no principled solutions to them, but this is no longer the case. In the table below we summarize some of the main problems with modularity and how they are solved with inferential approaches.
| Problem | Principled solution via inference |
| Modularity maximization overfits, and finds modules in fully random networks. [5] | Bayesian inference of the SBM is designed from the ground to avoid this problem in a principled way and systematically succeeds [13]. |
| Modularity maximization has a resolution limit, and finds at most \(\sqrt{2E}\) groups in connected networks [6] | Inferential approaches with hierarchical priors [14] [15] or strictly assortative structures [11] do not have any appreciable resolution limit, and can find a maximum number of groups that scales as \(O(N/\log N)\). Importantly, this is achieved without sacrificing the robustness against overfitting. |
| Modularity maximization has a characteristic scale, and tends to find communities of similar size; in particular with the same sum of degrees. | Hierarchical priors can be specifically chosen to be a priori agnostic about characteristic sizes, densities of groups and degree sequences [15], such that these are not imposed, but instead obtained from inference, in an unbiased way. |
| Modularity maximization can only find strictly assortative communities. | Inferential approaches can be based on any generative model. The general SBM will find any kind of mixing pattern in an unbiased way, and has no problems identifying modular structure in bipartite networks, core-periphery networks, and any mixture of these or other patterns. There are also specialized versions for bipartite [16], core-periphery [17], and assortative patterns [11], if these are being searched exclusively. |
| The solution landscape of modularity maximization is often degenerate, with many different solutions with close to the same modularity value [7], and with no clear way of how to select between them. | Inferential methods are characterized by a posterior distribution of partitions. The consensus or dissensus between the different solutions [18] can be used to determine how many cohesive hypotheses can be extracted from inference, and to what extent is the model being used a poor or a good fit for the network. |
Because of the above problems, the use of modularity maximization should be discouraged, since it is demonstrably not fit for purpose as an inferential method. As a consequence, the use of modularity maximization in any recent network analysis can be arguably considered a “red flag” that strongly indicates methodological carelessness. In the absence of secondary evidence supporting the alleged community structures found, or extreme care to counteract the several limitations of the method, the safest assumption is that the results obtained with that method tend to contain a substantial amount of noise, rendering any inferential conclusion derived from them highly suspicious.
As a final note, we focus on modularity here not only for its widespread adoption but also because of its emblematic character. At a fundamental level, all of its shortcoming are shared with any descriptive method in the literature—to varied but always non-negligible degrees.
References
Webmentions2
(Nothing yet)
2 Webmention is a standardized decentralized mechanism for conversations and interactions across the web.
Comments
(Comments may be moderated.)
If you reply to this post, it will show as a comment below the original article.